

type
Post
status
Published
date
Jul 2, 2020
slug
summary
tags
Java
多线程
category
技术
icon
fas fa-info
password
Java锁
独占锁(写锁):
指该锁一次只能被一个线程锁持有。对于ReentranrLock和 Synchronized 而言都是独 占锁。
共享锁(读锁):
该锁可被多个线程所持有。
公平锁:
是指多个线程按照申请锁的顺序来获取锁,类似排队打饭,先来后到。
非公平锁:
是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比现申请的线程 优先获取锁。不断尝试获取锁,如果尝试失败就像公平锁一样等着。
ReentrantLock锁可以通过创建时的构造方法来指定为公平锁还是非公平锁,默认为非公平锁
源码如下:
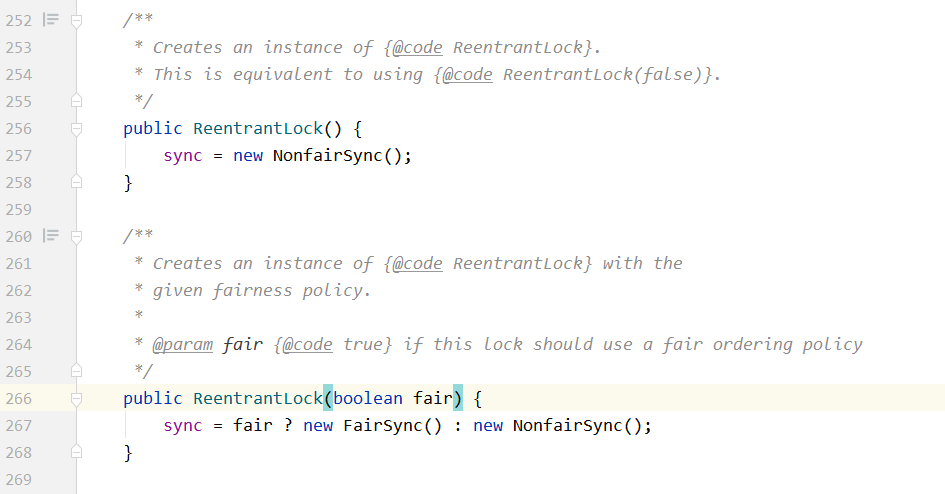
对于Synchronized而言,也是一种非公平锁。
可重入锁(也叫递归锁):
指的是同一线程外层函数获得锁之后,内层递归函数仍然能获取该锁的代码,在同一个线程在外层方法 获取锁的时候,在进入内层方法会自动获取锁。也就是说,线程可以进入任何一个它已经拥有的锁,所同步着的代码块。 就好比,打开家的大门,也可以打开家里房间的门。
ReentrantLock、Synchronized 就是一个典型的可重入锁;
自旋锁(spinlock):
是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下 文切换的消耗,缺点是循环会消耗CPU。
死锁:
是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力干 涉那它们都将无法推进下去,如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性 就很低,否者就会因为争夺有限的资源而陷入死锁。
此外,还有乐观锁,悲观锁
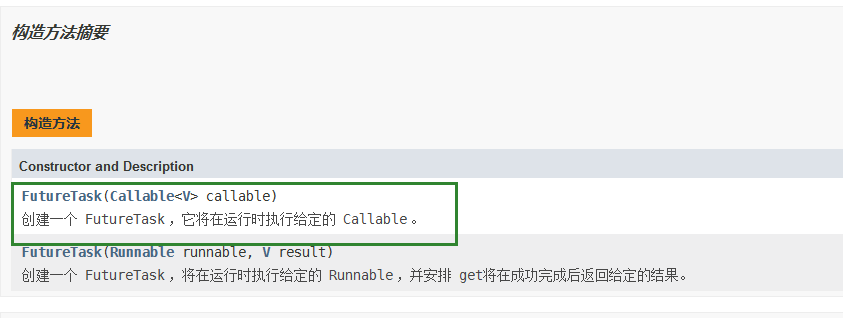
Callable
Java中获取多线程 除继承Thread类和实现Runnable接口 外的,第三种方式
与Runnable不同之处:


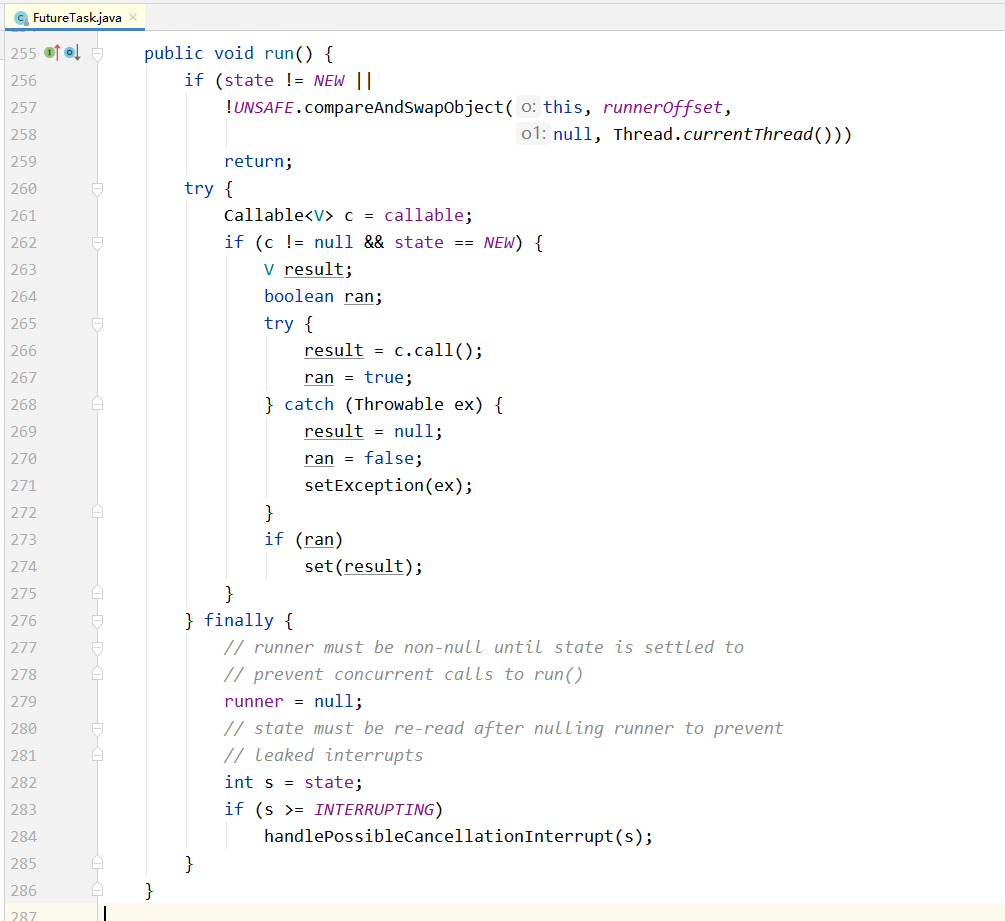
从源码可以发现,是否有返回值,是否抛异常,实现方法不同,一个是call()方法,一个是run()方法
可是Thread类没有关于Callable参数的方法,这点JDK源码已经表明了
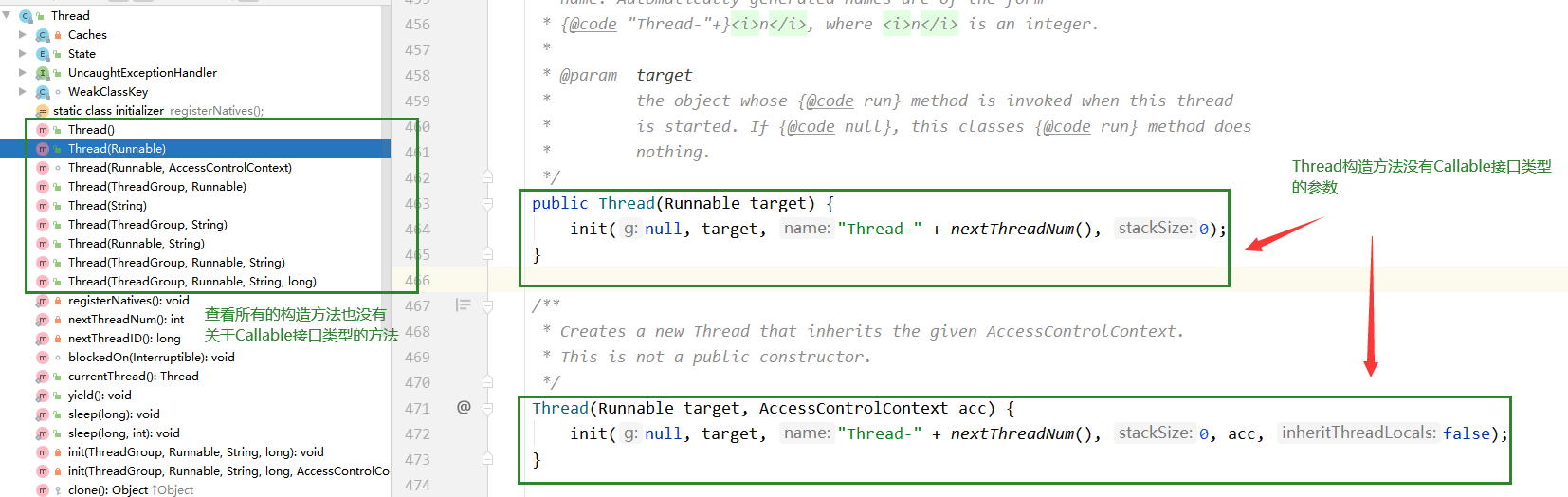
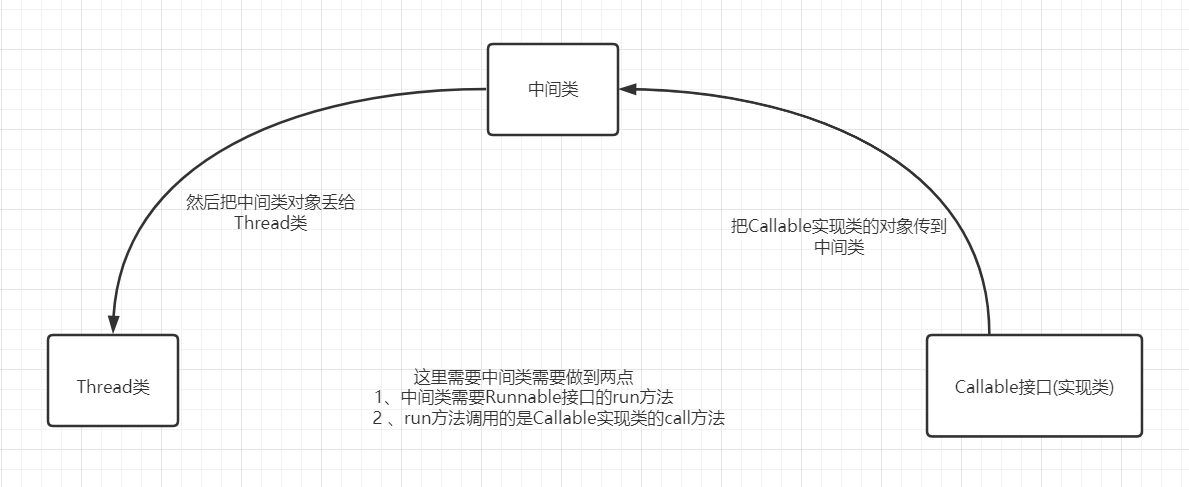
所以需要一个中间类来实现Callable接口与Thread类的关系,这个类需要实现Runnable接口(这样才能把对象传给Thread类),且构造方法参数有Callable接口类型参数(这样才能把Callable接口的实现类的对象丢进来);
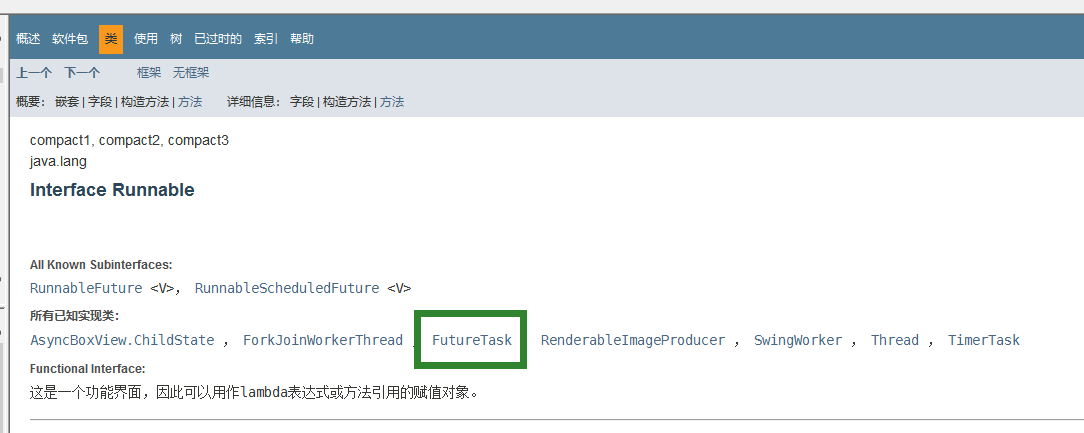
查看Jdk文档以及查看中间类的源码得知,FutureTask类可以做这个中间类,来完成Callable接口的call()方法调用
测试代码:
Lock
传统的Synchronized锁实现
Lock锁实现
Synchronized 和 Lock 区别
- synchronized是Java的关键字,而Lock是Java的一个类
- synchronized是自动释放锁的(线程正常执行完毕会释放锁,线程执行出现异常也会释放锁),而Lock需要在finally手动释放锁(即调用unlock()方法),否则或造成死锁
- 用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1 阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
- synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平也可非公平(两者皆可)
- Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题
生产者消费者
生产者和消费者 synchroinzed 版
关于虚假唤醒
因为if只会判断一次,当其它线程唤醒等待线程时,在停留在if作用域的线程被唤醒,不会再次判断,当有多个线程时,这种情况会引起虚假唤醒现象,即没有满足唤醒条件也会被唤醒,所以改用while循环,重复判断,以防脱离判断条件
新版生产者和消费者写法(Lock版)
Lock指定通知顺序唤醒访问
集合类不安全
List
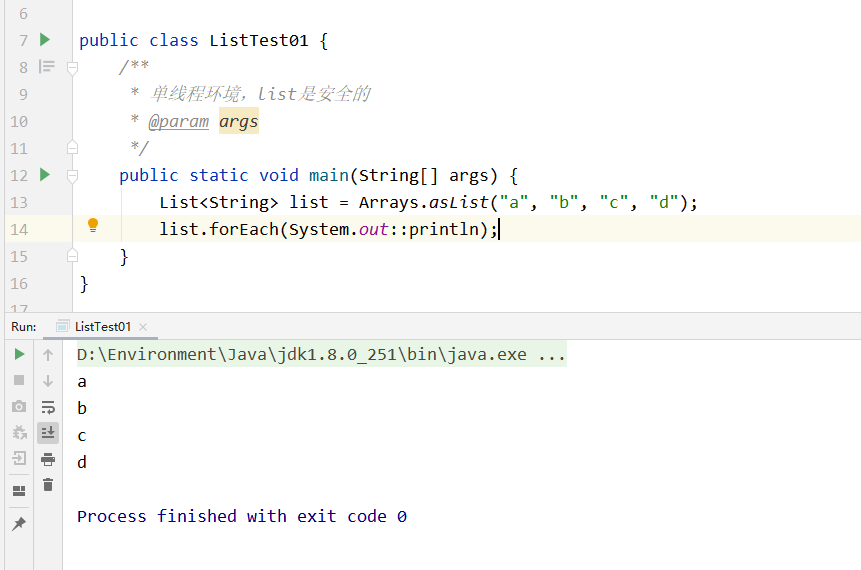
单线程环境下:
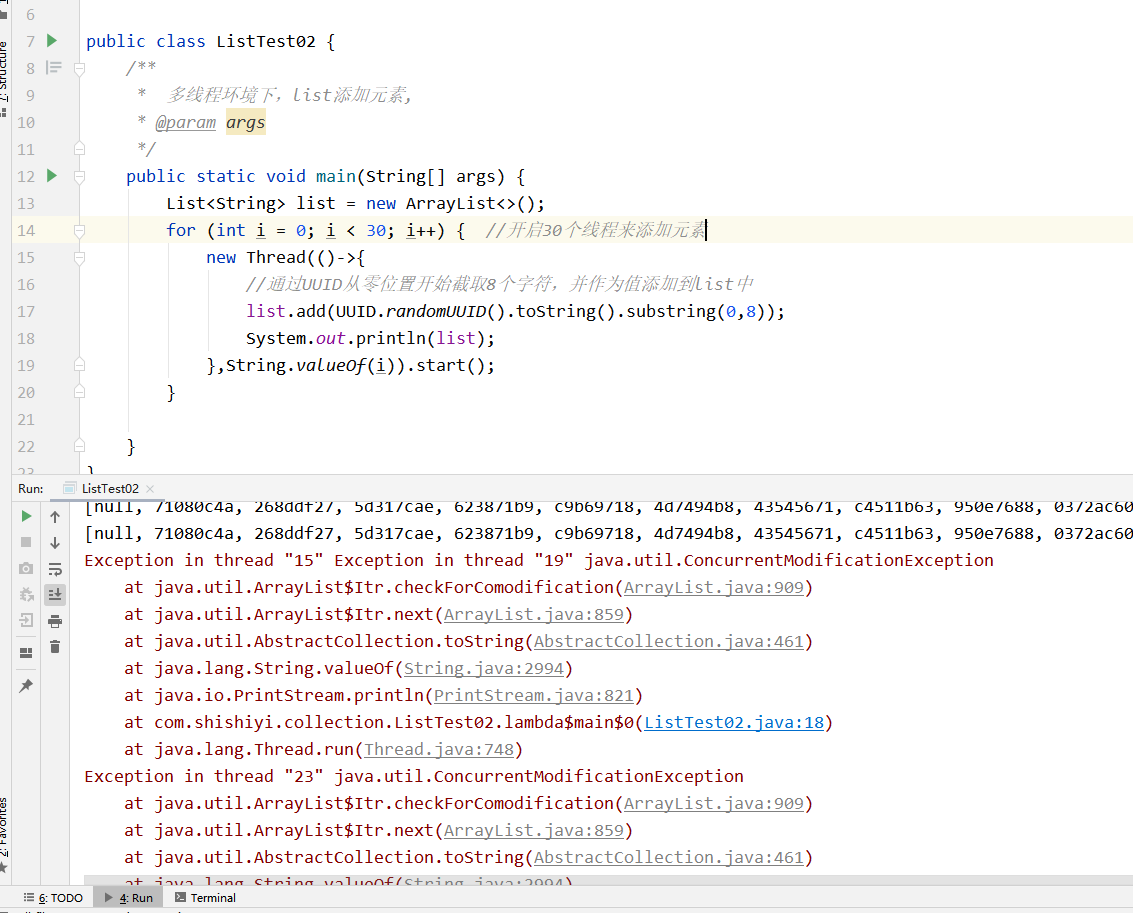
多线程环境下:
写入时复制(CopyOnWrite)思想
写入时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的一种优化策略。其核心思想 是,如果有多个调用者(Callers)同时要求相同的资源(如内存或者是磁盘上的数据存储),他们会共 同获取相同的指针指向相同的资源,直到某个调用者视图修改资源内容时,系统才会真正复制一份专用 副本(private copy)给该调用者,而其他调用者所见到的初的资源仍然保持不变。这过程对其他的 调用者都是透明的(transparently)。此做法主要的优点是如果调用者没有修改资源,就不会有副本 (private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
读写分离,写时复制出一个新的数组,完成插入、修改或者移除操作后将新数组赋值给array
CopyOnWriteArrayList为什么并发安全且性能比Vector好
我知道Vector是增删改查方法都加了synchronized,保证同步,但是每个方法执行的时候都要去获得 锁,性能就会大大下降,而CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性 能就好于Vector,CopyOnWriteArrayList支持读多写少的并发情况。
Set
多线程环境下:
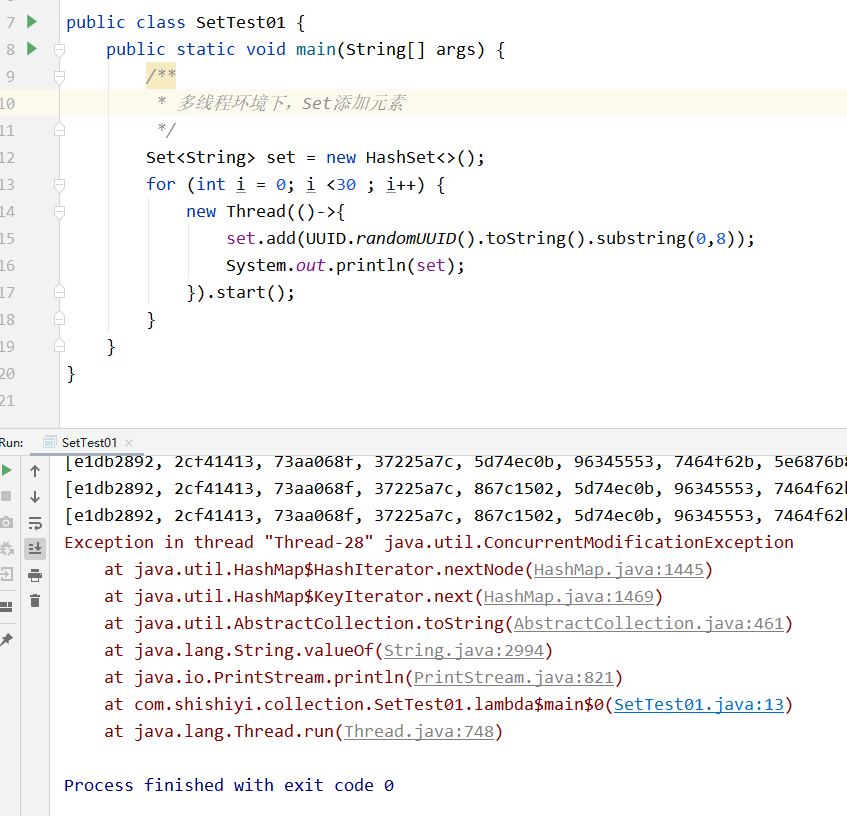
另外还有一点,HashSet底层就是HashMap,JDK源码如下:
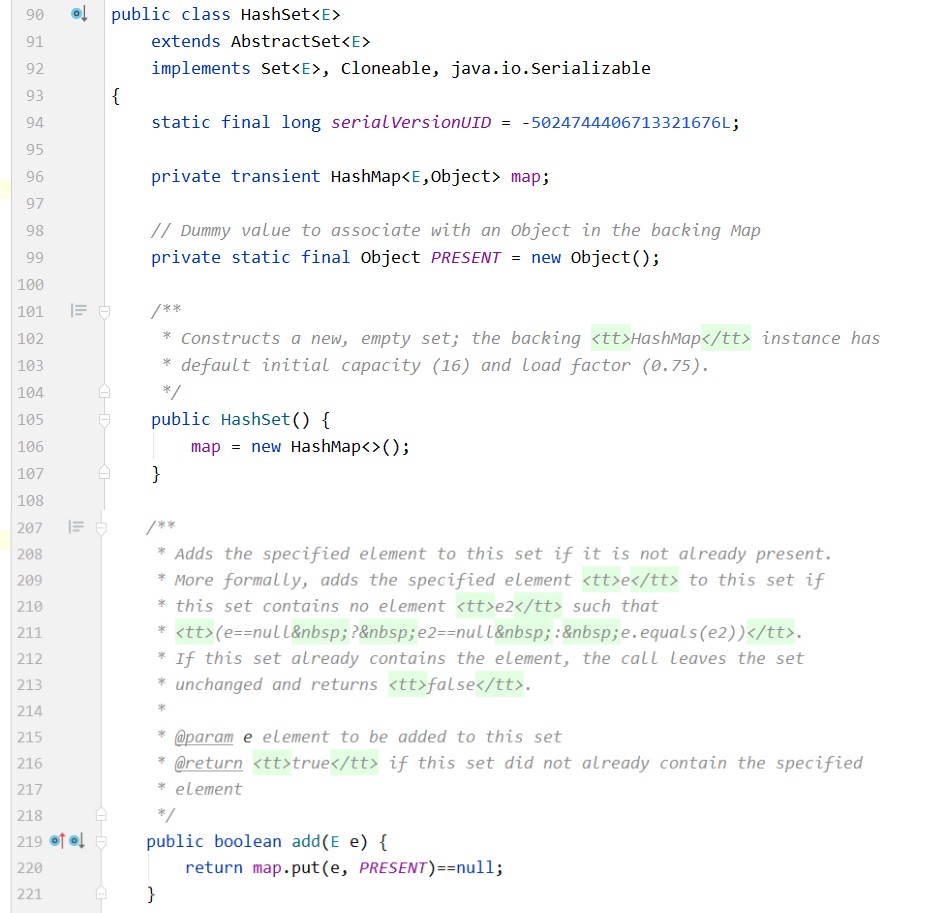
通过源码可以看出,HashSet底层是创建了一个HashMap,Key就是存放HashSet的值,也就是通过HashMap的key机制,来去除重复值的,而key对应的value就是一个叫PRESENT的常量
HashMap底层就是数组+链表+红黑树(JDK1.8开始,当链表长度大于8时,链表自动转为红黑树,这是为查询值时做的一个优化)
从JDK1.8源码可以看出,在创建时HashMap可以指定它的长度(即容量)和加载因子,否则就是默认的16长度和0.75加载因子

多线程环境下:
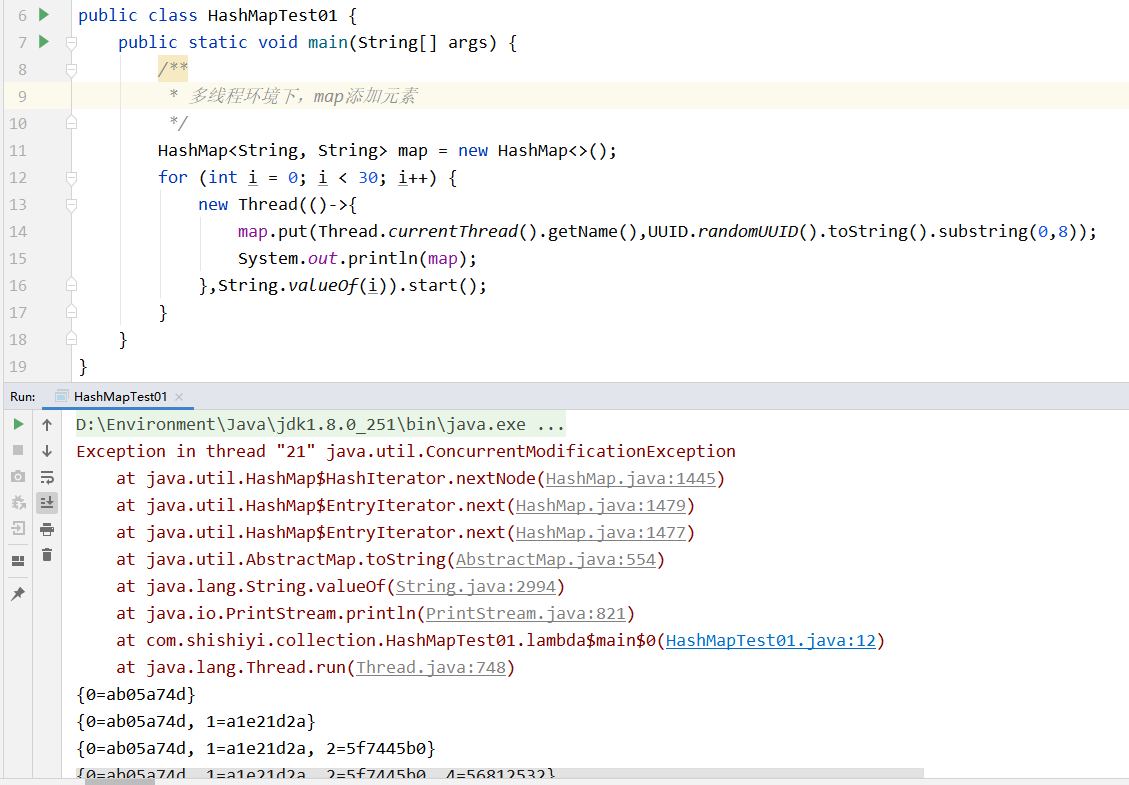
读写锁
多个线程同时读同一个资源类时,是不会出现任何问题的,但是实际情况往往是读写并发的,也就说读写资源类是同时进行的。
如果资源类不进行加锁的话,会产生错误:
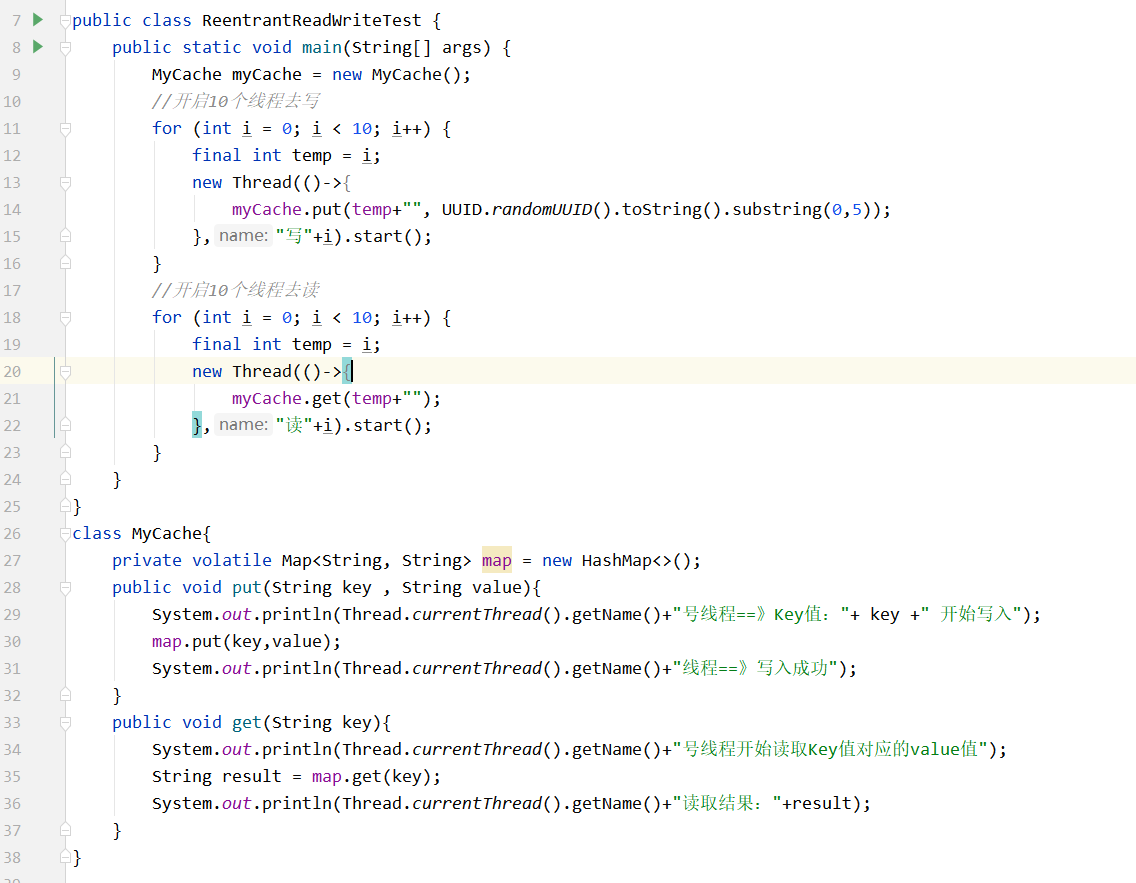
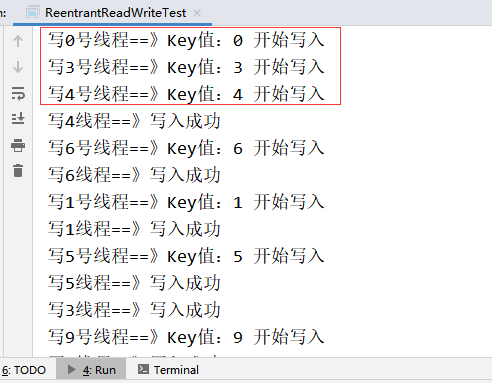
发现写入时,未完成写入,就有其它线程也进行写入,这种是会产生安全问题的
ReentrantReadWriteLock(读写锁)
线程池
JDK官方提供三种创建线程池的方法
线程池中只创建一个线程 newSingleThreadExecutor()
线程池中创建固定数目的多个线程 newFixedThreadPool()
线程池中创建不固定数目的多个线程 newCachedThreadPool()
自定义线程池 ThreadPoolExecutor()
通过查看JDK源码,发现三种创建线程池的方法都是调用了new ThreadPoolExecutor(七个参数)
三种创建线程池方法源码如下:


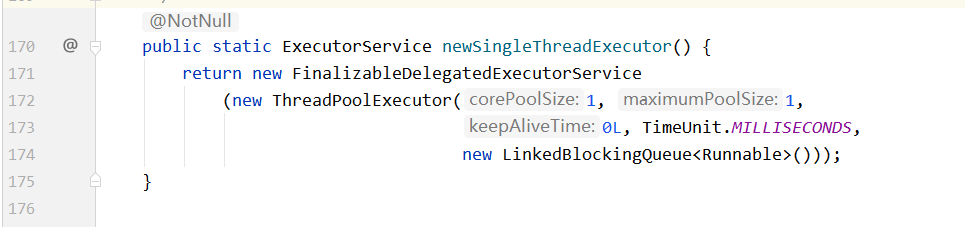
查看ThreadPoolExecutor()方法源码如下:
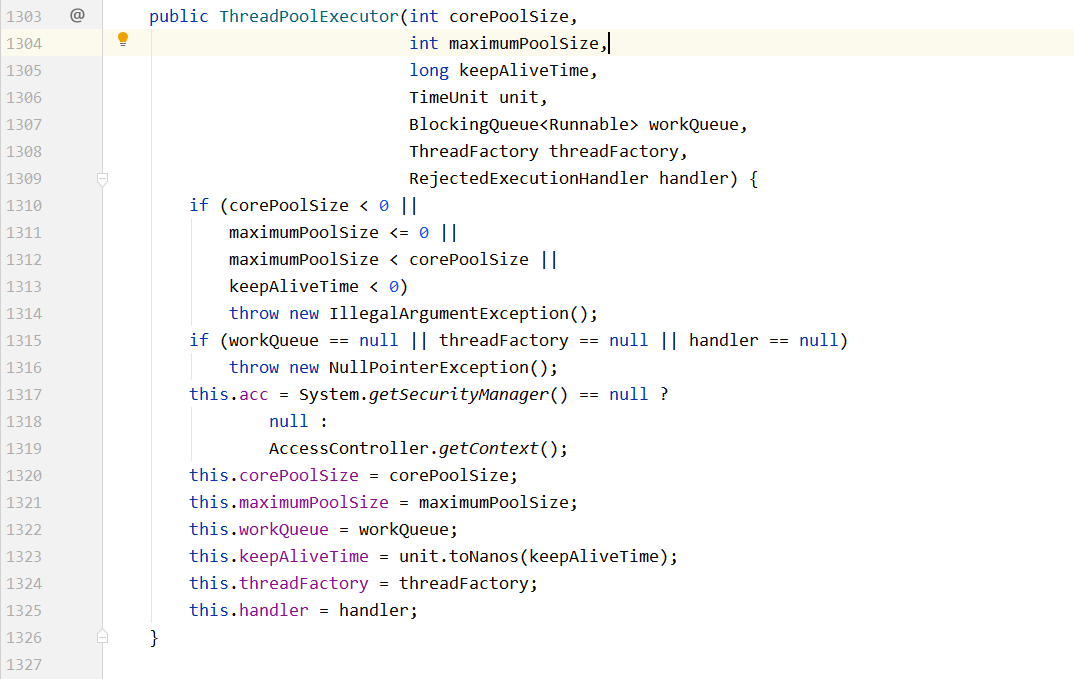
发现该方法有七个参数
int corePoolSize :核心线程数量。当创建线程池后,线程池中线程数是为0的,当有任务进来时,才开始创建线程执行任务,而线程池空闲时,会维护一个最小线程数量,即使这些线程数是空闲状态,也不会销毁它们,除非设置了allowCoreThreadTimeOut,而这个最小线程数就是corePoolSize
int maximumPoolSize :最大线程数量。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize来指定
long keepAliveTime :线程保留的时间。一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定
TimeUnit unit : keepAliveTime的计量单位
BlockingQueue< Runnable > workQueue :阻塞队列,存储等待执行的任务。
新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务。jdk中提供了四种工作队列:
ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
LinkedBlockingQuene
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize,因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
SynchronousQuene
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
ThreadFactory threadFactory :线程工厂,用来创建线程,一般默认即可。可以用来设定线程名等等
RejectedExecutionHandler handler : 拒绝策略,队列已满,而且任务量大于大线程的异常处理策略
举例记忆 ,银行窗口办理业务的过程非常适合理解这七个参数
测试:
自定义线程池最大容量为:最大线程数(maximumPoolSize ) + 阻塞队列容量(workQueue)
JUC的常用类
Semaphore类(信号量)
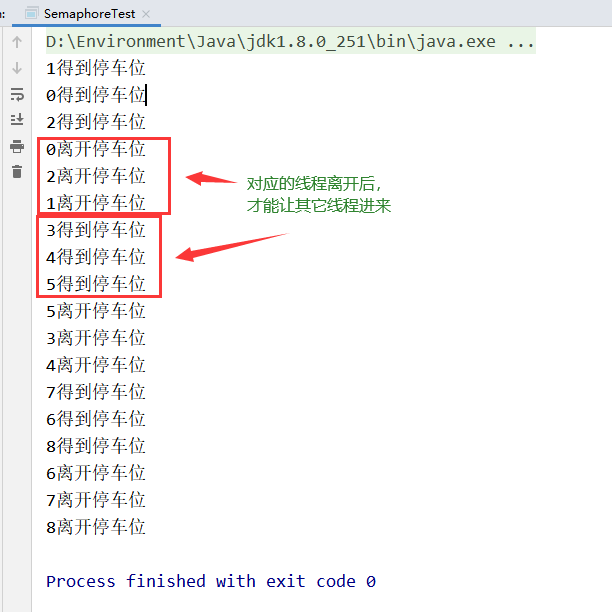
在上述测试中,semaphore定义了两个操作
- acquire(获取)
- 当前线程要么成功获取到信号量(即信号量-1,被占了一个)
- 要么等待其它线程释放信号量,或者一直等待到超时
当一个线程调用acquire()方法操作时
- release(释放)
当线程调用release()方法时,则当前线程会释放信号量(即信号量+1),以便其它等待的线程拿到信号量
CountDowLath类(倒计时记数器)
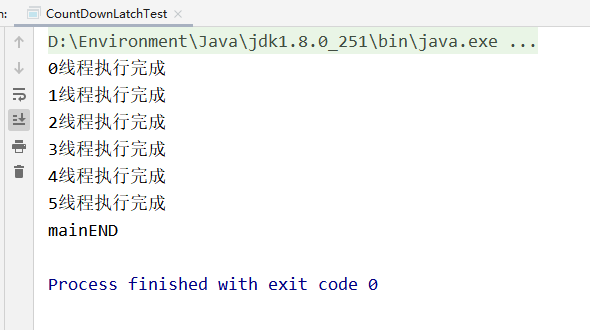
在上述测试中,countdowlath类有两个方法
- countDown()
当一个或多个线程调用countDown()方法时,计数器会减1,且线程不会被阻塞
- await()
当一个线程或多个线程调用await()方法,调用该方法的线程会被阻塞,直到计数器归零,阻塞的线程才会重新被唤醒继续往下执行
从执行结果可以看出,其它子线程调用countDown()并没有被阻塞而是继续执行直至完毕,但调用await()方法的main主线却被阻塞,直到计数器归零才重新执行
CyclicBarrier类
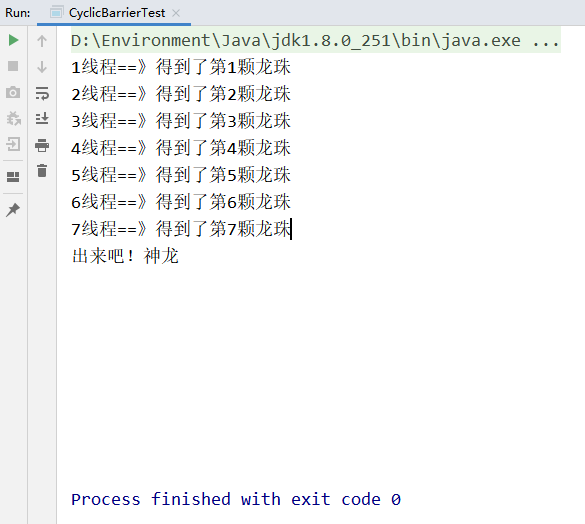
CyclicBarrier与上面计数器(CountDowLath)作用相反,当等待线程达到指定数目,则释放等待的线程,并执行对应的内容,譬如上述测试,集齐七颗龙珠召唤神龙
- 作者:十十乙
- 链接:https://shishiyi.cc/article/56a6008e-2ccf-44da-ac41-38619f428166
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。






![[电影][中国台湾][阳光普照]](https://www.notion.so/image/https%3A%2F%2Fprod-files-secure.s3.us-west-2.amazonaws.com%2Fbe23f5eb-2746-4139-b163-dae75ffc3a4b%2F04675b25-9975-4ea7-994f-7b8868fc6b15%2Fp2582670021.jpg?table=block&id=1b2da8b6-f9a9-48bb-a7df-5564a2ca9c72&t=1b2da8b6-f9a9-48bb-a7df-5564a2ca9c72&width=1080&cache=v2)
![[电影][中国大陆][邪不压正]](https://www.notion.so/image/https%3A%2F%2Fprod-files-secure.s3.us-west-2.amazonaws.com%2Fbe23f5eb-2746-4139-b163-dae75ffc3a4b%2F3e1a3adf-927c-4500-bf2b-9d938ff7a5be%2Fp2526259453.jpg?table=block&id=17debe06-72b3-42d7-ba53-2ad0f1b3ae1a&t=17debe06-72b3-42d7-ba53-2ad0f1b3ae1a&width=1080&cache=v2)